
A primer on vector search using Pinecone Serverless
Pinecone recently launched its serverless offering with the goal of making vector search implementation easier and cost-efficient. With LLMs rapidly becoming a core part of applications and most of them using RAG in their implementation – vector search is an important concept to understand. In today’s post, we’ll look at how to implement vector search using Pinecone Serverless.
What is vector search and why is it needed?
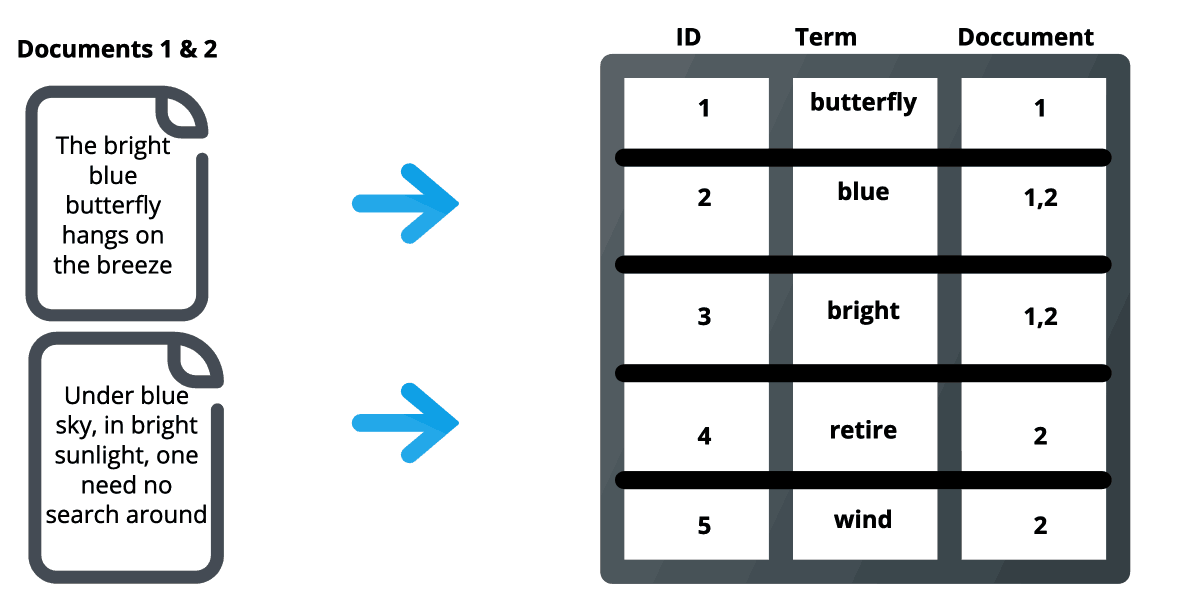
In traditional keyword search (like the one in Elasticsearch), given a search term you try to find documents that contain the term. The way it works is your search engine will compute an inverted index that stores which document contains what term. When you query using a search term, the search engine will use this inverted index to find the documents that contain the search term and return these documents sorted based on a similarity score.
Now this approach works well when you want to search based on exact keywords. But what if you want to search based on the meaning (semantics) of your search query? For example, if you search for “Queen of England” and all your documents contain the term “Elizabeth II”, the traditional search will return 0 results even when you have matching documents.
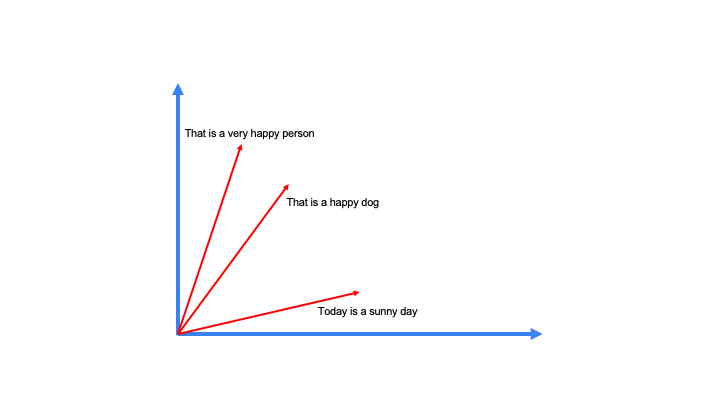
This is where vector search (or semantic search) comes in. In vector search, you use an embedding model to create vector embedding of text, which is just a numeric representation of the meaning of the text. This vector is then stored in a vector database (like Pinecone) using a special index (generally HNSW). When you query with a search term, the same embedding model is used to compute a vector embedding for the search term which is then used to query the vector database.
What are some use cases where vector search is used? The most common one in the context of LLM apps is for Retrieval Augmented Generation (or RAG). But that’s not the only thing vector search is used for. Some other notable use cases are:
- Image and Video Recognition
- Recommendation Systems
- Biometrics and Anomaly Detection
- Drug Discovery and Genomics
This blog is by Sourabh, our CTO who spends most of his time building an AI agent and gives the best restaurant recommendations. If you like this post, try KushoAI today, and start shipping bug-free code faster!
Implementation using Pinecone Serverless
Let’s take a look at how to implement vector search. There are 2 main things to consider to make sure the search is efficient:
- What model is used for creating vector embeddings - The model you use has to capture the semantics of the text properly for you to get accurate results. You’ll need to use some trial and error to figure out what model works best. If an out-of-the-box model doesn’t get the accuracy that you want, you might need to fine-tune a model using your custom dataset.
- What database is used for storing/searching vectors - This will determine the speed and cost of searching.
For this example, we’ll use the OpenAI embeddings endpoint for computing vector embeddings and Pinecone for storing/searching vectors.
Here’s how you can create vector embedding using the OpenAI :
from openai import OpenAI
client = OpenAI(api_key="YOUR-API-KEY")
response = client.embeddings.create(
input="Your text string goes here",
model="text-embedding-ada-002"
)
print(response.data[0].embedding)This is how you create a serverless index on Pinecone:
from pinecone import Pinecone, ServerlessSpec
pc = Pinecone(api_key='YOUR_API_KEY')
pc.create_index(
name="quickstart",
dimension=8,
metric="euclidean",
spec=ServerlessSpec(
cloud='aws',
region='us-west-2'
)
)
To store embeddings in Pinecone, here’s how you do it:
import pinecone
def store_vector_in_pinecone(api_key, index_name, vector_id, vector):
"""
Store a vector in Pinecone.
Parameters:
- api_key (str): Your Pinecone API key.
- index_name (str): The name of the index to store the vector in.
- vector_id (str): The unique identifier for the vector.
- vector (list): The vector to be stored.
Returns:
- bool: True if successful, False otherwise.
"""
pinecone.init(api_key=api_key)
try:
index = pinecone.Index(index_name)
index.upsert(items=[(vector_id, vector)])
return True
except pinecone.ApiException as e:
print(f"Error: {e}")
return False
finally:
pinecone.deinit()
# Example usage
api_key = "YOUR_PINECONE_API_KEY"
index_name = "your_index_name"
vector_id = "unique_vector_id"
vector_to_store = [0.1, 0.2, 0.3, 0.4, 0.5] # Replace with your actual vector
store_vector_in_pinecone(api_key, index_name, vector_id, vector_to_store)You can search your Pinecone index like this:
import pinecone
def search_vector_in_pinecone(api_key, index_name, query_vector, top_k=5):
"""
Search for a vector in Pinecone.
Parameters:
- api_key (str): Your Pinecone API key.
- index_name (str): The name of the index to search in.
- query_vector (list): The vector for which you want to find similar vectors.
- top_k (int): The number of top results to retrieve (default is 5).
Returns:
- list: A list of tuples containing (vector_id, score) for the top matching vectors.
"""
pinecone.init(api_key=api_key)
try:
index = pinecone.Index(index_name)
results = index.query(queries=[query_vector], top_k=top_k)
return results[0]
except pinecone.ApiException as e:
print(f"Error: {e}")
return []
finally:
pinecone.deinit()
# Example usage
api_key = "YOUR_PINECONE_API_KEY"
index_name = "your_index_name"
query_vector = [0.2, 0.3, 0.4, 0.5, 0.6] # Replace with your actual query vector
search_results = search_vector_in_pinecone(api_key, index_name, query_vector)
if search_results:
print("Top search results:")
for result in search_results:
vector_id, score = result
print(f"Vector ID: {vector_id}, Score: {score}")
else:
print("No search results found.")Other options for implementing vector search
Pinecone is not the only option for implementing vector search. Here are some other options you can try if Pinecone is not your cup of tea:
Another notable mention is Elasticsearch which has added support for sparse vectors in their latest version. This is a good option especially if you’re doing a POC and want both keyword and vector search without the hassle of setting up multiple databases.
At KushoAI, we're building an AI agent that tests your APIs for you. Bring in API information in any format and watch KushoAI turn it into fully functional and exhaustive test suites in minutes.
Member discussion