
No More Cutting in Line: Crafting Fairness in Queues

So what is this queue fairness and why should you care about it?
Recently we published an article on how to manage long-running tasks using a worker and queue, if you haven't read I suggest that you read it first, you can read it here.
Queuing systems offer reliability, and are very intuitive, but they are also really easy to mess up.
Before coming back to the main question, let's consider this simple scenario, you have set up the infra for managing long-running tasks using a queue so, whenever a user performs an operation on your platform, a job gets enqueued to the queue, an available worker will pick the job from the queue and process it, you might be wondering what's the issue here?
This blog is by Sahil, a full-stack developer, who writes funny blogs and manages to keep house plants alive. If you like this post, try KushoAI today, and start shipping bug-free code faster!
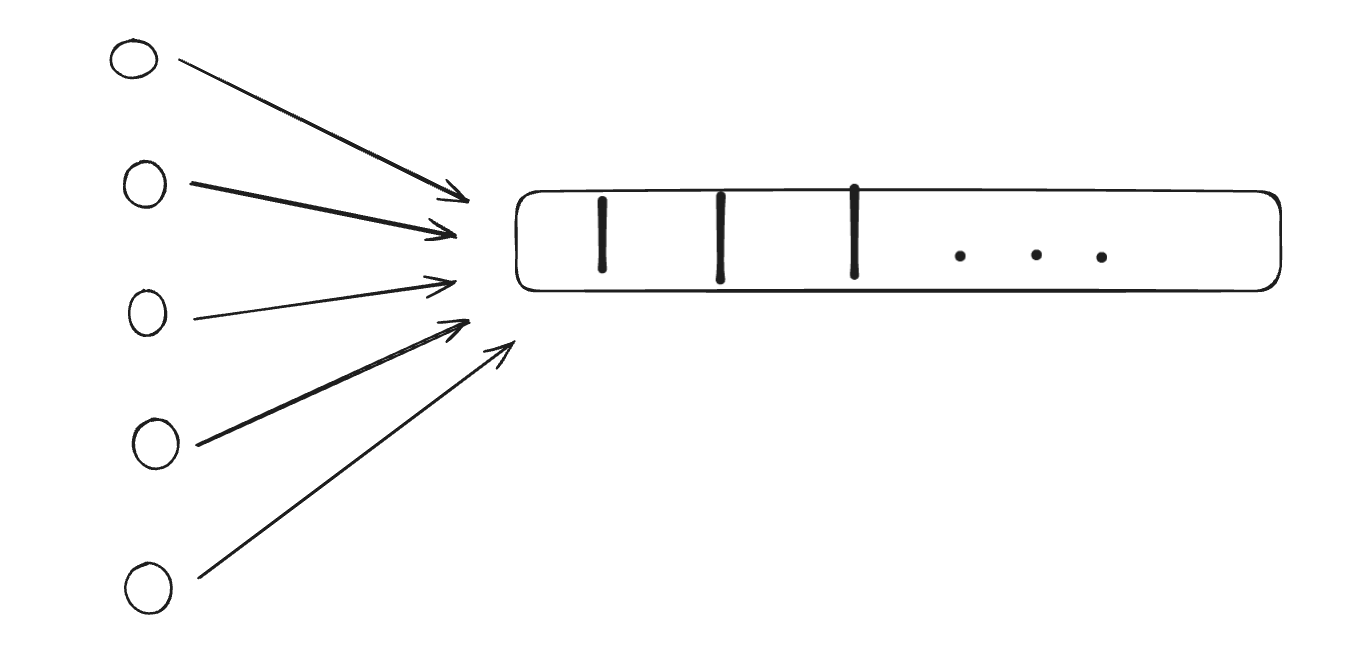
Now check out the below image, in an imaginary world your app gets a lot of traction, and you onboard a bunch of users who are using your app concurrently. Now your queue has multiple jobs enqueued, so you will notice that other users' jobs are waiting in the queue to be picked up by the worker because Karen decided to perform a bunch of operations at once (well she's not wrong here) other users might not find this experience _FAIR_
Let's look at the definition of a fair queue:
Fair queuing is a family of scheduling algorithms used in some processes and network schedulers. The algorithm is designed to achieve fairness when a limited resource is shared, for example, to prevent flows with large packets or processes that generate small jobs from consuming more throughput or CPU time than other flows or processes.
In layman's terms basically, we don't want the users to wait and also not throw more hardware at this problem so we would like to implement some sort of mechanism that will ensure fairness of the queue and try to avoid resource starvation.
### Enough Talk, show me the <s>code</s> algorithm
There are multiple ways to solve this problem, the easiest is to throw more hardware at the problem but, this is not a sustainable solution and you are still going to face a resource starvation problem – hence we are going to put our fancy computer science hats and talk about Round Robin.
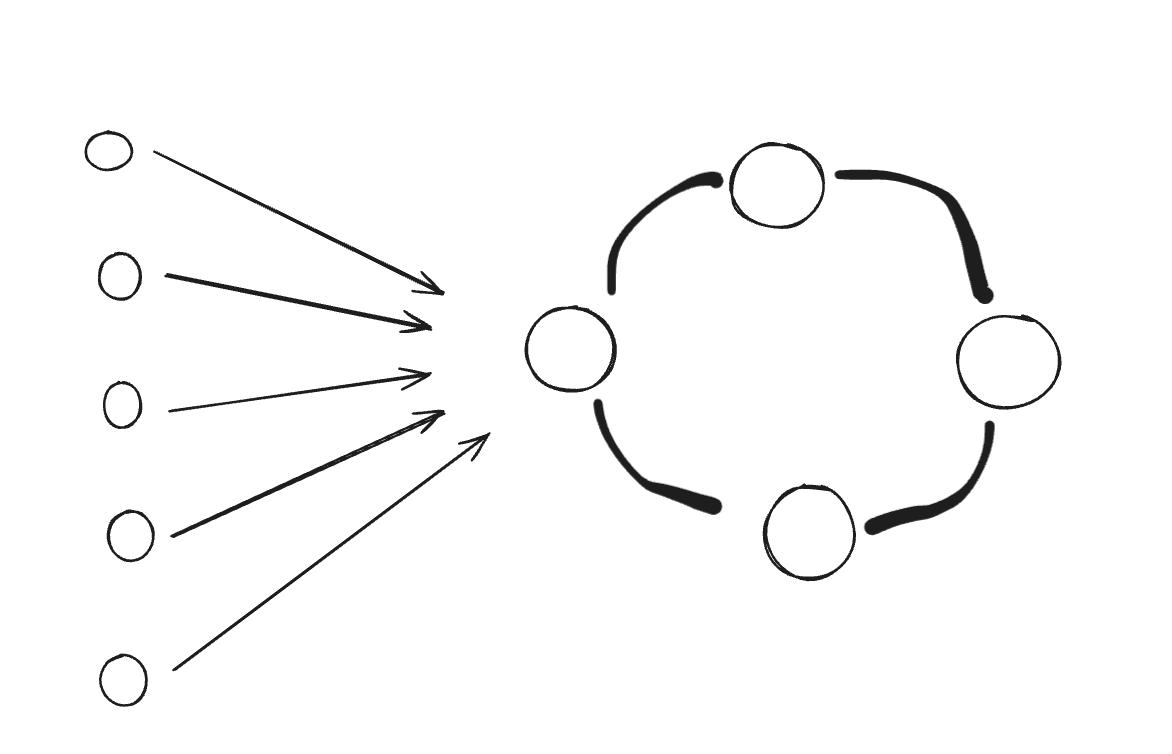
Excusing my terrible visual skills, let's try to understand how round-robin works, in simpler terms, we can think of taking turns, where your job will get resources for a fixed amount of time, and then the resources get passed on to some other job.
Let's devise a dead simple algorithm and then we will try to write code for the same.
We initialize multiple Redis clients to represent different shards of the job queue, allowing for horizontal scaling and load distribution. When a job is enqueued via the /enqueue endpoint, we calculate the shard index based on the job data and push the job onto the queue of the corresponding Redis shard. The /process endpoint iterates through each Redis shard in a round-robin fashion, popping a job from each shard's queue until finding a job to process. This setup ensures fairness in job processing while avoiding resource starvation.
from flask import Flask, request, jsonify
from redis import Redis
import json
app = Flask(__name__)
redis_clients = [Redis(host='localhost', port=6379, db=i) for i in range(3)] # Assuming 3 Redis shards
# Function to calculate the shard index for a given job
def get_shard_index(job_data):
# Example: Distribute jobs based on some hash value
return hash(job_data) % len(redis_clients)
# Endpoint for adding jobs to the queue
@app.route("/enqueue", methods=["POST"])
def enqueue_job():
job_data = request.json # Assuming JSON data containing job details
shard_index = get_shard_index(json.dumps(job_data))
redis_clients[shard_index].lpush('job_queue', json.dumps(job_data))
return jsonify({"message": "Job enqueued successfully"}), 200
# Endpoint for processing jobs using round-robin scheduling
@app.route("/process", methods=["GET"])
def process_jobs():
for redis_client in redis_clients:
job_data = redis_client.rpop('job_queue')
if job_data:
job_data = json.loads(job_data)
# Process the job (replace this with actual job processing logic)
print("Processing job:", job_data)
return jsonify({"message": "Job processed successfully", "job_data": job_data}), 200
return jsonify({"message": "No jobs to process"}), 404
if __name__ == "__main__":
app.run(debug=True)
There are several other ways to approach this problem, we will talk about them in future articles.
Member discussion